
Data Evaluation System
Time: HKUST(GZ) Medical Data Inteligence Lab, 2024
MDI Data Evaluation is the MDI data quality evaluation service
I was responsible for platform development and back-end model access, as well as participating in data processing. Collaborator: Su Ri, Wenjin Qi:qijin70@gmail.com,
Introduction:
This project aims to briefly evaluate the annotation results of doctors on a cell electron microscope dataset using various methods, including feature information calculation, training, and data screening, to improve the quality and accuracy of the dataset annotations.
Methods and Results
- Feature Information Calculation
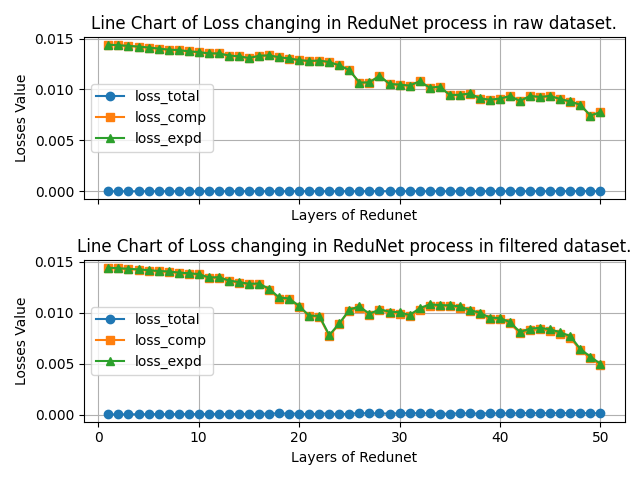
- Method: The ReduNet calculation model was used to evaluate image feature information through the “maximum coding rate reduction” criterion.
- Results: The dataset’s feature representation showed stability during the encoding process, indicating good quality in feature representation. After screening, the dataset’s intra-class coding rate significantly decreased, showing improved accuracy in representing intra-class features.
- Model Training
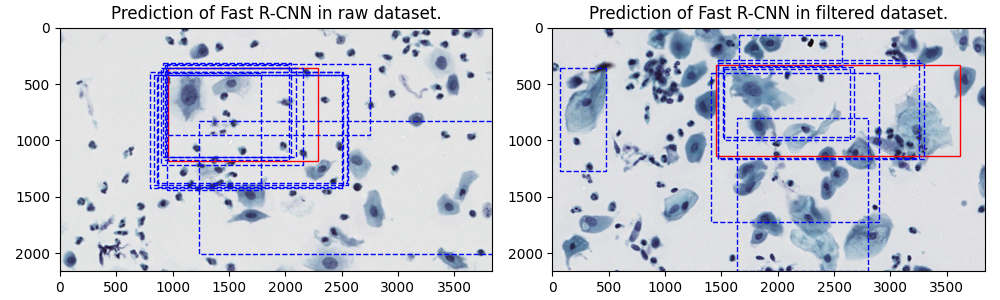
- Method: The Fast R-CNN model was used for preliminary learning and evaluation. This model employs selective search to extract candidate regions, uses convolutional neural networks for feature extraction, and performs object recognition and localization through classification and bounding box regression.
- Results: The screened dataset effectively reduced errors in model prediction results, indicating that the original dataset’s labels contained noise. After CleanLab screening, the model’s prediction results were more reasonable and cautious.
- Data Screening
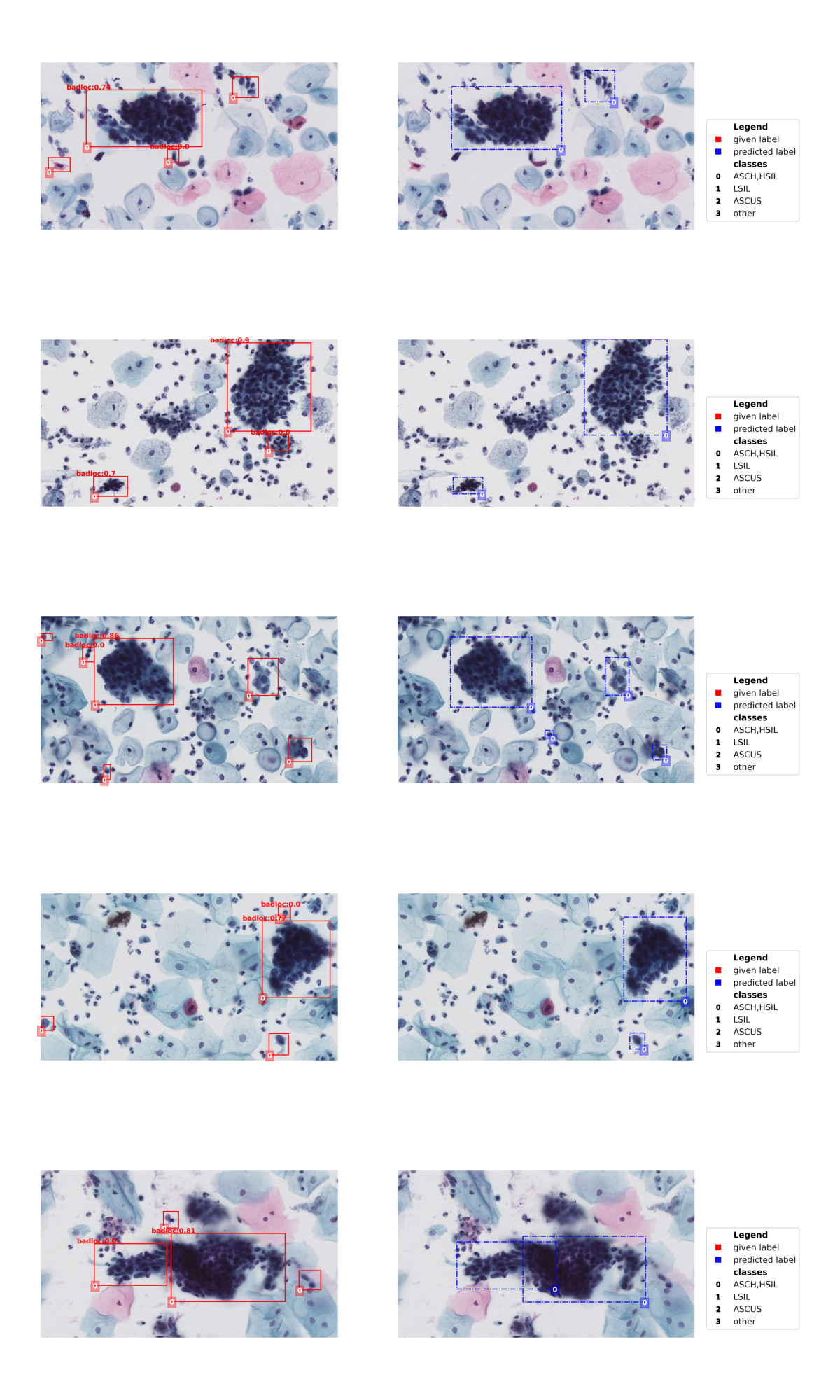
- Method: CleanLab’s algorithm, designed specifically for object detection tasks, was used to evaluate and clean the dataset’s label quality.
- Results: Before screening, the dataset labels showed positional and categorical deviations. After CleanLab screening, label positions were more accurate, and unmarked parts were corrected, enhancing the dataset’s annotation quality.
Conclusion
Based on the above methods and results, it is preliminarily concluded that the dataset’s image feature representation ability is relatively stable and good. CleanLab screening has improved the dataset’s feature representation, training effect, and label accuracy. However, the basic model’s training effect still has room for improvement, and the dataset’s label accuracy has some quality issues, mainly in the annotation quality. The current stage’s object detection dataset quality is moderate, but further optimization of label quality can significantly enhance the overall performance of the dataset.